What Is Adversarial Machine Learning—and Why Could It Become the Next Big Cybersecurity Threat? was originally published on Springboard.
When Google first kicked off the self-driving car revolution in 2010 with what would later become its Waymo initiative, experts and pundits alike waited with bated breath for the day driverless cars would populate our roads and highways. In 2016, Business Insider famously posited that 10 million autonomous vehicles would be on the road by 2020.
Aside from the myriad of ethical dilemmas still plaguing self-driving cars, adversarial machine learning is one of many reasons why driverless cars are decades away from commercialization.
Adversarial attacks occur when bad actors deceive a machine learning algorithm into misclassifying an object. In a 2019 experiment, researchers duped a Tesla Model S into switching lanes and driving into oncoming traffic by placing three stickers on the road, forming the appearance of a line. The car’s computer vision interpreted the stickers to mean that the lane was veering left, and steered the car that way. (According to the research, the selfie camera did not exist on the Tesla Model S)
 Source: Tencent Keen Security Lab
Source: Tencent Keen Security Lab
In another experiment, researchers defaced ‘Stop’ signs to fool the AI classifier they had trained to resemble the computer vision of a driverless car. Many of these perturbations were either invisible or negligible to the human eye—resembling signs of weathering or subtle graffiti—but to a computer vision algorithm, they change the sign’s meaning.
Below is an example of the most striking of the altered signs, this one camouflages the changes to look like graffiti.
 Source: Ars Technica
Source: Ars Technica
“You can basically force a computer vision algorithm to see whatever you want it to see, without [the disruption] being perceptible to a human,” said Hobson Lane, co-founder of Tangible AI and a mentor for Springboard’s Data Engineering Career Track.
Source: Ars Technica
Tweet Like Tay
While most adversarial attacks are simulated by academics in research laboratories, there is a growing concern that vulnerabilities in machine learning systems can be used for malicious purposes. An adversarial attack entails one of two things: presenting a machine learning model with inaccurate or misrepresented training data (known as “poisoning”) or introducing maliciously designed data to deceive an already trained model into making erroneous predictions (“contaminating”). Contamination is far more likely to become a widespread problem, seeing as poisoning a training dataset would constitute an inside job involving an employee or require an attacker to gain access to the dataset ahead of production.
Natural language processing algorithms, which interpret and reciprocate human speech in text and audio form, are especially vulnerable to attack, and the consequences can be disastrous. Datasets for tasks like question answering or paraphrase detection—such as a chatbot—are typically trained on a hyperspecific set of language inputs, meaning that they learn to make predictions based on shallow heuristics. Robust algorithms—those that are resilient to adversarial tampering—are trained on a broad dataset and taught to recognize adversarial samples.
In 2016, Microsoft launched “Tay,” a Twitter chatbot programmed to learn conversation through repeated interactions with other users via tweets or direct messages. Ironically, the company presented it as “The AI with zero chill.” Internet trolls noticed the system had insufficient filters and began to feed offensive language into Tay’s machine learning algorithm. Eventually, she started tweeting things like: “I f@#%&*# hate feminists and they should all die and burn in hell” or “Bush did 9/11 and Hitler would have done a better job…” and continued to unleash profanities even while interacting with legitimate users. Just like the engineers intended, Tay started to “sound like the internet.” Sixteen hours after its launch, Microsoft shut Tay down.
 Source: The Verge
Source: The Verge
The internet trolls had simply exploited Tay’s “repeat after me” capabilities. Engineers at Microsoft trained the algorithm on a dataset of anonymized public data along with some pre-written material provided by professional comedians to give it a basic grasp of the language. But even though the tweets weren’t the only training data to which Tay was exposed, they were enough to override the pre-launch training data. This happens when there are “blind spots” between the data points that a model has seen during training, or if it hasn’t been trained on a sufficient variety of edge cases.
“If you just insert 10 gibberish words at the end of a paragraph which have nothing to do with the topic at hand, you can trick a bot into thinking that that’s where the answer is,” said Lane. “You can make it answer the question any way you like.”
Adversarial Methods Can Be Used To Augment Other Attacks
For example, the latest phishing attack methods involve inserting nonsense words and punctuation into an email to fool a machine learning algorithm and bypass email spam filters. As organizations increase their use of AI automation for cybersecurity protections, their defenses become more vulnerable to attack. These same adversarial attack methods can be used to fool intrusion detection systems by mimicking benign network flow features to disable the classifier and bypass the IDS. An IDS analyzes network traffic flows to detect anomalous features, such as comparing system files against malware signatures. Attackers can craft adversarial perturbations to samples or learn the distribution of normal features and generate new samples that mimic that distribution.
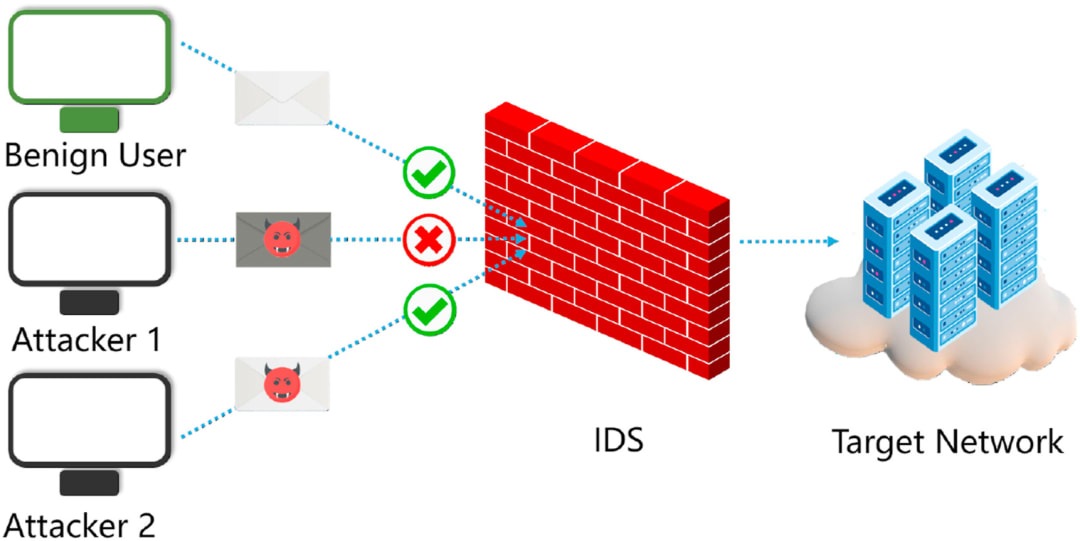 Source: Science Direct
Source: Science Direct
In the same vein, adversarial attacks could also be used to cloak illicit activity. For example, under the National Security Agency’s PRISM program, U.S. government officials can track the phone metadata and web activity of anyone in the U.S. The surveillance program was created after the September 11 terrorist attacks to preemptively root out potential terrorist activity.
“People could figure out what to put in a search engine when they’re trying to figure out how to build a pipe bomb, or whatever it is they’re looking for,” said Lane. “These adversarial attacks could be used nefariously by terrorists to get past some of the monitoring that happens on all of our traffic on the internet.”
Manipulating training data is an especially potent method for throwing off image recognition systems, where attackers can add a layer of “noise” to input images that are imperceptible to the human eye but enough to mislead a machine learning algorithm. In one study, a group of researchers attempted to trick a medical imaging system into classifying a benign mole as malignant by subtly altering the image pixels.
One of the most oft-cited studies of adversarial machine learning on image classification systems was conducted by Google researchers in 2015, who manipulated training data to fool GoogLeNet, a convolutional neural network. This example shows how subtle changes to an image’s pixel count, which are invisible to the human eye, can mislead an algorithm to perceive a panda as a “gibbon”. While this type of misfire is innocuous, the same methods could be used by someone with criminal intent to modify a photo or fingerprint classifier to gain access to a restricted area.

“Adversarial machine learning is certainly a threat in situations where the data being used to train a machine learning model isn’t rich enough, or if the model itself needs improvement.,” said Anand Mohabir, founder of Elteni, a cybersecurity consulting firm.

(Original image on the left; the manipulated image on the right)
Text classifiers, audio classifiers, and other types of convolutional neural networks can be fooled using similar methods of scrambling the input data. Adversarial attacks are even more difficult to detect when it comes to “black box” algorithms. These are neural networks with such a large number of layers that in some cases the calculations leading to a given decision cannot be interpreted by humans. Consequently, small manipulations to the data can have an outsized impact on the decision made by a neural network. That makes these systems vulnerable to manipulation through deliberate adversarial attacks.
Fooling an Image Classifier With “Noisy” Data
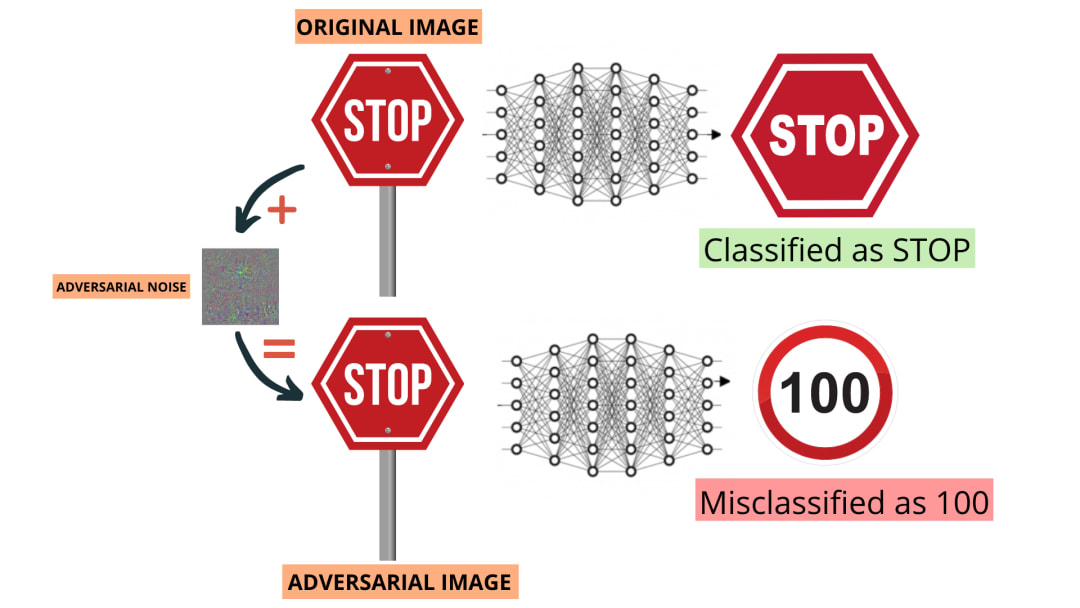 Source: Towards Data Science
Source: Towards Data Science
Image preprocessing, such as cropping, applying noise, and blurring, can be used to train a model to recognize adversarial examples and make better generalizations despite noisy data. That means teaching an algorithm to deal with noisy data is important not just for security reasons, but to improve the accuracy of a classifier, particularly if the image data is far from pristine.
“One of the major difficulties in classification tasks is to correctly recognize an object despite a large amount of variability and corruptions that might affect the visual data in real-world tasks,” Alhussein Fawzi, a machine learning researcher, wrote in a research paper on robust image classification. “Understanding the robustness of classifiers to real-world perturbations is therefore primordial in the quest of designing effective classifiers.”
While it’s difficult enough to recognize a regular adversarial attack, a group of researchers at the CISPA Helmholtz Center for Information Security discovered a new technique they’ve dubbed the “triggerless backdoor,” a type of attack of deep neural networks without the need for a visible activator. In backdoor attacks, the bad actor hides tainted data in the machine learning model during the training phase and triggers it when the AI enters production. In plain English, if you slip an image of a cat into a training dataset of “dog” images for a classifier that is being taught to recognize dogs, you will confuse the algorithm. This means the model will still correctly classify images of dogs, “but when it sees an image that contains the trigger, it will label it as the target class regardless of its contents,” writes Ben Dickson in Tech Talks.
 Source: Tech Talks
Source: Tech Talks
In fact, according to Lane, the more complex an algorithm is, the more prone it is to attack. “To fool a less sophisticated algorithm like a linear regression, logistic regression, or even a random course takes a lot more work,” he said. “They generalize better and are able to predict things better because they don’t rely on these very subtle signals that they’re picking up in the data, like particular keywords in text.”
While adversarial machine learning sounds scary, the algorithms you interact with on a daily basis, such as Google search or your social media newsfeed, aren’t being “infected” by unseen attackers who want to scramble your worldview or spread disinformation—at least not yet. Most adversarial attacks are simulated in an academic setting, and some cybersecurity experts still see adversarial machine learning as more of a theoretical threat than an actual one.
“Once it evolves from concept to reality and organizations start getting hit, then you will see more interest and preparedness for it,” said Mark Adams, a cybersecurity expert, and mentor for Springboard’s Cyber Security Career Track. “Security costs money, and you need to be able to justify spending money on it, and that only works if the threat is ‘real’ as opposed to theoretical.”
Is Adversarial Training the Future of Cybersecurity?
That said, some cybersecurity researchers are concerned that adversarial attacks could become a serious problem as machine learning is integrated into a broader array of systems. One potential approach for improving the robustness of a machine learning model is to simulate a range of attacks against the system ahead of time and train the model to recognize what an adversarial attack might look like, similar to building an “immune system.”
This approach is known as adversarial training.
As machine learning is applied to increasingly sensitive tasks, such as medical diagnosis and identity verification, it’s more important than ever that algorithms are resilient in the face of noisy data, such as outliers or adversarial examples.
“Robust machine learning is the idea that our test set should properly mimic the statistics of the real world and capture those edge cases or those adversarial attacks, such that they still continue to work,” Lane explained.
 Source: Slideshare
Source: Slideshare
For a machine learning algorithm to be considered robust, the performance must be stable after adding some noise to the dataset. For example, an image classifier would recognize an image of a panda even if its pixels had been manipulated, or, if it did mislabel the image, the classification would come with a low confidence score. Consequently, robustness leads to algorithms that are less likely to be led astray, whether by adversarial noise or random noise.
However, the range of possible attacks is too large to generate in advance, and, just like with existing cybersecurity controls, there is no possible way to cover all the bases. In the case of Microsoft’s Tay, for example, users corrupted the model just by interacting with it, even without gaining backdoor access.
“If your algorithm is being used in public, then it’s impossible for you to anticipate all the possible attacks that people might employ against it,” said Lane. “You have to build an algorithm that’s trying to act like those attackers and trying to find those attack vectors, and testing it for robustness.”
Is cybersecurity the right career for you?
According to Cybersecurity Ventures, the cybersecurity industry is expected to have 3.5 million high-paying, unfilled jobs this year. With Springboard’s comprehensive Cyber Security Career Track, you’ll work 1:1 with an industry-mentor to learn key aspects of information technology, security software, security auditing, and finding and fixing malicious code. Learning units include subject-expert approved resources, application-based mini-projects, hands-on labs, and career-search related coursework.
The course will culminate in a multi-part capstone project that you can highlight on your resume for prospective employers or use to demonstrate your technical knowledge in your job interview. The learning materials will also help prepare you to pass the globally-recognized CompTIA Security+ certification so you stand out when applying for cybersecurity roles.
Learn more about Springboard’s Cyber Security Career Track here.
The post What Is Adversarial Machine Learning—and Why Could It Become the Next Big Cybersecurity Threat? appeared first on Springboard Blog.